Manage Global Replication Settings
The Replication service is responsible for replicating attributes of the group, user, contact, computer, and organizational unit objects from a provider (such as Active Directory) to Elasticsearch.
You can configure certain settings for the Replication service in Admin Center. You can schedule it to run every x minutes, force run it at any time, set a threshold for triggering replication error notifications, and view the Elasticsearch health status.
On every successful run of the Replication service, Directory Manager generates the replication status of object types for each domain in an identity store and alerts you to any errors that may have occurred during the replication process.
NOTE: The Replication service does not replicate excluded domains for an identity store. See the Exclude an Active Directory Domain from Replication topic.
How to Resolve Replication Errors
Possible actions to eliminate replication errors are:
- Make sure the Replication service and Elasticsearch service are running.
- Make sure Search Guard or any other security plugin you use for Elasticsearch is operational.
- Consult the Replication service logs. They provide elaborate information about the object type in the specific domain of the identity store the error occurred for, and whether that error comes from the identity provider or Elasticsearch. See the Replication Service Logs topic.
What do you want to do?
- Monitor Elasticsearch Health Status
- Specify a Replication Interval for Objects
- Force Run the Replication Service (for Object Replication)
- View the Replication Status for Objects
- Specify Interval for Deleting Tombstone Objects
- Force Run the Replication Service (for Deleting Objects)
- Restore Object Data to Elasticsearch
- Clear Unused Indices
- Change the Search Guard Password
- Set a Threshold to Trigger Replication Error Notifications
Monitor Elasticsearch Health Status
Directory Manager enables you to monitor the Elasticsearch service for the following:
-
The status of the Elasticsearch service. See the Elasticsearch Service card on the Admin Center dashboard.
-
Elasticsearch cluster health stats, which include:
- Cluster name, health status, node info and shards info
- Cluster indices information, like health, number of documents, and status
Directory Manager checks if the Elasticsearch service is running, if all nodes are working, and if the cluster is intact. It also checks the health of each index.
To view Elasticsearch health status:
-
In Admin Center, click Replication in the left pane.
-
On the Replication page, click Elasticsearch Health Monitor.

This dialog box lists the Elasticsearch clusters in your environment, with the following information for each cluster:
-
Health: the cluster health status denoted by the following colors:
- Green – the service is running and the cluster is intact. Moreover, two or more nodes exist within the cluster.
- Yellow – the cluster is running but with warnings. It also indicates that a single node exists within the cluster. Elasticsearch recommends a three-node topology for improved performance and high availability.
- Red – the service has stopped or the cluster is broken (for reasons such as network connectivity.
-
Nodes: the number of nodes in the cluster.
-
Master: the name of the master node in the cluster.
-
-
To refresh the information displayed, click the Refresh icon.
-
Click a cluster name to view it in detail.
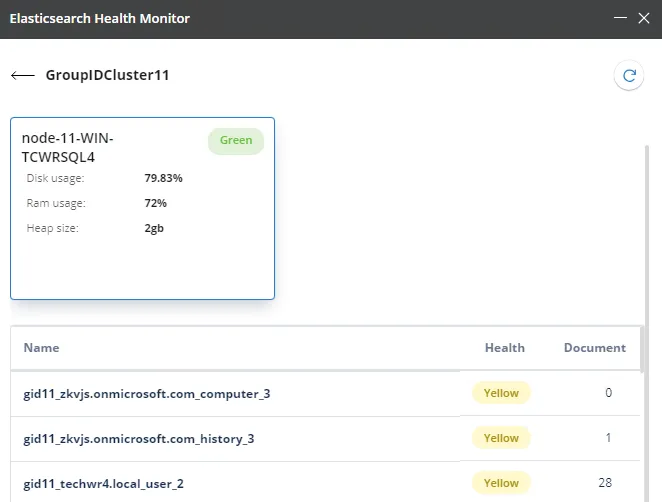
This dialog box displays the total number of nodes in the cluster. Each node is represented by a card, that displays the following for the node:
-
The name of the node
-
The system resources the node uses, such as hard disk space, RAM, and heap size
-
Node health with respect to disk space usage, denoted by the following colors:
- Green – when hard disk space usage is 79.99% or less
- Yellow – when hard disk space usage is 80-89.99%
- Red – when hard disk space usage is 90% or more
-
-
The indices in the cluster are listed in the gird.
-
The Name column displays the names of the indices.
-
The Health column displays the health of the index, which is denoted by the following colors:
- Green – the index is replicated to all nodes within the cluster.
- Yellow – the index is replicated to some but not all nodes within the cluster.
- Red – the index is not replicated to any node within the cluster.
-
The Document column shows the number of documents in the index.
-
-
Click the back arrow to return to the Elasticsearch Health Monitor dialog box.
Specify a Replication Interval for Objects
The Replication service interval applies to all identity stores defined in Admin Center. Object attributes to be replicated are specified in the respective identity store settings. See the Manage Local Replication Settings topic.
To set global replication interval:
-
In Admin Center, click Replication in the left pane.
-
On the Replication page, the Replication Service Interval card displays:
- the date and time the Replication service last ran
- the date and time the service will run next
- the interval (in minutes) between each run of the service
-
By default, the interval is set to 10 minutes, which indicates that the service is triggered every 10 minutes. In this way, changes made to objects in the directory during the last 10 minutes are replicated to Elasticsearch. In Active Directory, the whenChanged attribute stores the time and date the object was last changed. This service checks the value of this attribute and replicates any changes to Elasticsearch.
To change the interval, click Edit next to Service Interval on the on the Replication Service Interval card. Specify the interval (in minutes) between each run of the service and click the check mark.
Force Run the Replication Service (for Object Replication)
- In Admin Center, click Replication in the left pane.
- On the Replication page, click Force Replication Now on the Replication Service
Interval card to run the Replications service instantly.
Changes made to objects in the directory between the last and current run are replicated to Elasticsearch. Force-starting the service has no impact on the interval set in the Service Interval box for triggering the service.
View the Replication Status for Objects
After every run of the Replication service, you can view the replication status of each object type for each domain in an identity store. You can view which object types were successfully replicated and which ones failed to replicate.
To view the replication status:
-
In Admin Center, click Replication in the left pane.
-
On the Replication page, click Advanced Replication Status. The Advanced Replication Status dialog box displays the status of object types for each domain in an identity store.
-
The domains or object types that failed to replicate in the last run of the Replication service are displayed in red. Reasons could be inaccessibility or partial failure. Replication errors are brought to the administrator’s notice in the following ways:
- On the Identity Stores page, the card for the identity store turns red and Errors is displayed as the identity store status.
- A notification is sent to relevant personnel. See the Set a Threshold to Trigger Replication Error Notifications topic.
These alerts are triggered when replication fails in the last run of the Replication service, or if the service does not run at the required triggering interval. To resolve replication errors, see the How to Resolve Replication Errors topic.
-
The ‘Never replicated’ status indicates that the particular object type is not replicated yet. Similarly, a child domain that is not being used will have its status marked in red. To avoid these recurring errors, set the dates for these objects to a distant future date in the Directory Manager database. Or you can exclude a domain from replication. See the Exclude an Active Directory Domain from Replication topic.
-
Specify Interval for Deleting Tombstone Objects
Objects that are deleted from the directory must also be removed from Elasticsearch. For this purpose, you can specify a triggering interval for the Replication service to remove tombstone objects from the Elasticsearch repository. By default, the interval is set to 60 minutes, indicating that the service is triggered every 60 minutes. As a result, objects deleted in the directory during the last 60 minutes are removed from Elasticsearch.
To identify objects that have been deleted in the directory but exist in Elasticsearch, the Replication service compares the objects in both, and deletes objects that do not exist in the directory anymore.
To specify an interval:
-
In Admin Center, click Replication in the left pane.
-
On the Replication page, the Deleted Objects Replication Interval card displays:
- the date and time the Replication service last ran to remove tombstone objects from Elasticsearch
- the date and time the service will run again
- the interval (in minutes) between each run of the service
-
By default, the interval is set to 60 minutes, which indicates that the service is triggered every 60 minutes. In this way, objects that are deleted in the directory during the last 60 minutes are removed from Elasticsearch.
To change the interval, click Edit next to Service Interval on the Deleted Objects Replication Interval card. Specify the interval (in minutes) between each run of the service and click the check mark. This Replication service interval applies to all identity stores in Directory Manager.
Force Run the Replication Service (for Deleting Objects)
- In Admin Center, click Replication in the left pane.
- On the Replication page, click Force Replication Now on the Deleted Objects Replication
Interval card to run the Replication service instantly.
Objects deleted in the directory between the last and current run of the service, will be removed from Elasticsearch. Force-starting the service has no impact on the interval set in the Service Interval box for triggering the service.
Restore Object Data to Elasticsearch
You may need to restore object data to Elasticsearch. The restore object data function restores the following for all identity stores in Directory Manager:
- the current attribute values of objects (groups, users, contacts, computers, and OUs) from the provider (for example, Active Directory)
- the Directory Manager pseudo attributes of these objects from the Directory Manager database to Elasticsearch
To restore object data:
- In Admin Center, click Replication in the left pane.
- On the Replication page, click Restore Now in the Restore Objects Data area to restore data to Elasticsearch.
Clear Unused Indices
Directory Manager stores object attributes and their values in Elasticsearch, where each object type in an identity store is distinctly indexed. In a situation where an identity store is deleted from Directory Manager, its indices are not required anymore. So, you can clear them from Elasticsearch to avoid glut.
To clear unused indices:
- In Admin Center, click Replication in the left pane.
- On the Replication page, click Clear Now in the Clear Unused Indices area. The system checks if there exist any indices in Elasticsearch for an identity store that no longer exists in Directory Manager.
- The Delete Unused Indices dialog box displays the indices that will be deleted from
Elasticsearch. Click Delete to proceed or click Don't Delete to close the dialog box
without clearing the indices.
In case no unused indices are found, a notification pops up in the bottom right corner to inform that no unused indices were found.
Change the Search Guard Password
Search Guard is a security plugin used to induce an authentication mechanism in Elasticsearch. The option to change the Search Guard password is available when you install and manage Elasticsearch with Directory Manager. Users who use their own instance of Elasticsearch cannot change the Search Guard password using Directory Manager.
You can change the password of the admin account that Directory Manager uses to access Elasticsearch.
To change the password:
- In Admin Center, click Replication in the left pane.
- On the Replication page, click Change Password in the Search Guard Settings area.
- On the Change Password dialog box, provide the current password for the Search Guard admin account in the Your current password box.
- Specify a new password in the New Password and Confirm Password boxes.
- Click Change Password.
Set a Threshold to Trigger Replication Error Notifications
The Replication service runs every x minutes to replicate objects in an identity store. In case it fails to replicate during a run, a replication error is displayed, as discussed in the View the Replication Status for Objects topic.
Directory Manager generates notifications to alert administrators to replication errors. By default, the triggering threshold is set to ‘3 attempts’, which means that notifications will be sent when errors occur in three consecutive runs of the Replication service. You can change the threshold value as required.
Replication error notifications are sent to recipients whose email addresses are specified in the To and CC boxes on the Notifications page. See the Specify Notification Recipients topic.
To set a triggering threshold:
- In Admin Center, click Replication in the left pane.
- On the Replication page, the Replication Error Notification area displays ‘3 Attempts’ as
the default threshold for initiating notifications. This means that notifications will be sent
when three consecutive runs of the replication service result in error. Notifications will not be
sent when errors occur say, in two consecutive runs but no error shows in the third consecutive
run.
To change the threshold value, click Edit. Specify a threshold value to trigger replication error notifications and click the check mark.
See Also